This is a guest post by Ken Jones – Ken specialises in writing workflow applications and offering training and consultancy for publishers on print and digital workflows. Ken’s company ‘Circular Software’ provides software tools and services for a range of illustrated book publishers. Contact Ken on twitter @CircularKen on LinkedIn at linkedin.com/kenjones or through the website circularsoftware.com.
This article has been kindly edited by Laura Brady and has been cross-posted on epubsecrets.com
The Digital Publishing Summit was held in Berlin on Weds 16th and Thurs 17th May. It was a wide-ranging and stimulating event full of interesting news about the digital publishing landscape.
The area of central Berlin we were in had a pleasant bohemian vibe. After my vegan panini and smoothie, I strolled to the event hotel as hordes of cyclists whizzed by along the sunny streets. Oh, wait, this is not a holiday review, allow me to continue… #not-eprdctn
This previous name for this yearly gathering used to be the ‘EPUB summit’ but this year it has been renamed the Digital Publishing Summit or ‘DPUB summit’ as it relates to digital publishing beyond EPUB. Before the main conference started around 40 of us started off the Wednesday morning with an extra Readium workshop led by Laurent Le Meur, CTO, EDRLab (@lmrlaurent). Laurent started but outlining some of the challenges with Readium 1 — notably performance, accessibility gaps and lack of Windows and Linux SDKs. They decided to to start R2 with fresh codebase and to create new mobile & desktop SDK named Readium-2 (aka R2).
The overall aim of the project is to deploy a set of open and interoperable digital publishing technologies in Europe, around an open, flexible & accessible standard applicable to all kinds of digital publications

R2 is being optimised for performance, ease of maintenance, and is well documented with consistency between target environments (so different OS, mobile, desktop). It is a live ongoing project with releases approx. every two weeks. Everything they are doing is on Github. Readium 2 apps are emerging already and an Alpha desktop version in publicly available.
They have an ambitious roadmap for 2018. Expect progress to be made in roughly in the following order: import, library, reflowable EPUB, LCP (Readium Licensed Content Protection), user settings, RTL, fixed-layout, CBZ (comic books and manga), OPDS (Open Publication Distribution System), bookmarks, vertical text, themes, footnotes, accessibility navigation, search, support for WP, audiobooks, TTS, media overlays, more dyslexia support.

EDRLab are seeking a wider community for development, feedback, and financial support.
Phew! Got all that? I’ll explain in more detail about some of this below. The roadmap is available on Github. EDRLab are seeking a wider community for development, feedback and financial support. They need constructive testing (so don’t just moan about how it may look wonky or has missing features, they already know this!…) and, again, everything is open and logged on Github.
Hadrien Gardeur of Feedbooks then spoke about the Readium Web Publication Manifest. Think of it as an unpackaged and deconstructed ebook that exists in RAM. By abstracting the contents it means R2 reading apps can be much more responsive. By loading the publication into memory and preparing for transmission over the web. And it doesn’t have to be EPUB, any structured publication could be deconstructed. They already support CBZ (a format for comic books as images) and are in a good place to handle any new W3C formats that come in the future.
R2 ingests packaged EPUBs in this way ready to them streamed, parsed, and fetched as HTML resources. They refer to the flow of rendered content to the reader app as the ‘streamer’. Think of the R2 reading system in 2 parts: frontend and backend. The frontend reader is fed by the backend, which could be either within an offline app or streamed from a server. By pre-fetching and pre-rendering content in backend memory everything is presented super fast.
Readium CSS is the open resource that Readium apps are using to present content and to handle user settings. Glue JS is a new project being built for R2 which makes sense of pagination, scrolling, touch and key events and CSS, locations, and custom properties.

Aferdita Muriqi of EDRLab (@AferditaMuriqi) talked about where they are with Readium mobile apps and their future plans. The R2 iOS app is out now and it is still being developed with later builds regularly and betas here. The R2 Android app is also available now (in beta) from Googleand Github. R2 iOS and Android are being developed in tandem and share the same functionality and core code. But the different OS mean they have to handle things differently.
It’s important to understand that the EDRLab stance on mobile apps is that they will only ever be ‘test apps.’ They have no plans to produce a fully featured mobile reader instead will provide an open source example to others of what is possible and exactly how to do it.
The ultimate goal is a robust attractive reading system and to become an open replacement.
Daniel Weck of EDRLab (@DanielWeck) talked about Readium desktop apps and their future plans. Unlike the mobile apps the plan for desktop IS NOT to be just a test app. The ultimate goal is a robust attractive reading system and to become an open replacement. R2 desktop apps are already very impressive but are still in early stages. Latest builds available here.
R2 apps (desktop and mobile) already come with support for OPDS (Open Publication Distribution System) basically a way for a metadata feed from a vast library of books to stream and also can point to book content. Sideloading is also possible. R2 Desktop has a load button for local files and mobile apps can load from weblinks or Dropbox etc. via the OS. If you interested in the future of EPUB readers, or the current lack of them, consider join me and others in testing and giving feedback to shape these valuable and open source mobile and desktop apps.
If you interested in the future of EPUB readers, or the current lack of them, consider join me and others in testing and giving feedback to shape these valuable and open source mobile and desktop apps
We then moved on to an interesting chat about EPUB Canonical Fragment Identifiers. In short, EPUB CFI is an accurate way to point to any content within EPUBs. Lars Wallin of @ColibrioReader demonstrated how to use EPUB CFI to achieve interoperable, sharable, annotations, bookmarks etc. EPUB CFI also support identification of interactive elements, images and even parts of images within EPUB. Yuri Khramov of @EvidentPoint then spoke how they are contributing to ‘Readium NG’ to support existing R1 users in their migration to R2 with as little pain as possible
Later, in the main DPUB conference, we heard more on how Readium Licensed Content Protection aka Readium LCP can store a user’s passphrase inside an EPUB reader to effortlessly unlock content. Hermann Eckel of German ebook company Tolino explained how Readium LCP is already installed in their hardware and how it is now their preferred copy protected solution.
Later we saw a live demo of a reader entering accessing an ebook using the standard library log-in.

Eden Livres talked about how they invested last year to integrate LCP server side and now have over 80,000 titles now live with Readium LCP.
De Marque talked about how National Libraries Quebec achieve 6M+ ebook loans – quite a lot for a small city. Previous DRM systems had cost them over $800K CAD over the years and with countless hours of support and left them feeling powerless and not in control. LCP was a community project to take that control back. They are currently focus testing LCP with user in Quebec City, to be released this summer for all public libraries in Quebec province and other partners.
“DRM should be boring. It should be invisible and nothing to the user.”
A refreshingly neat quote that summed it up was “DRM should be boring. It should be invisible and nothing to the user.” #eprdctn
Garth Conboy of Google spoke about EPUB3.2 and future plans for EPUB at W3C and invited participation in the community group.

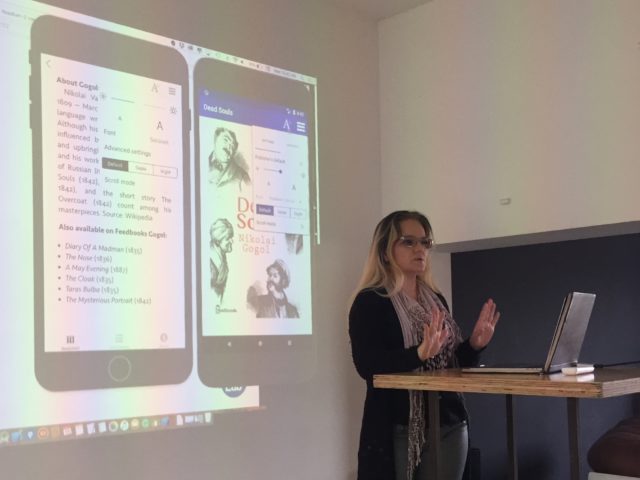
Ben Walters of Microsoft (@_BenWalters_) gave a great presentation on how their Edge browser natively supports EPUB. Double click any DRM free reflowable or Fixed Layout EPUB on Windows 10 and it auto opens in this well featured reader. He said that reading books on a desktop or laptop may not be common but actually for reference or education the ability to have multiple pages of the same book, of different books, or other web content side by side can be very useful. One challenge for browser based reading is that people don’t expect a browser to work offline, even though they can for cached and local content. The challenge here is in education.
Microsoft Edge for iOS and Android edge on phone coming ‘very soon’. First releases were last year but last month’s update brings improvements including notes, better navigation, page sharing and media overlays! This is great stuff from Microsoft!… You hear that @Adobe…
Ben confirmed to me afterwards that, at launch, sideloading will not be possible for Edge on Android and iOS. It will only feature content from the Microsoft store.
Ben also won the prize for the most amusing slide when introducing his agenda.
Stephan Knecht from Bones AG demoed how their audio reader accepts EPUB by parsing a book into txt files. Able to handle cues like SSML, to indicate preferred speech speed, male, female voices for example. More here.
Stephan made an interesting point that his customers (often visually impaired, elderly, veterans) like the static simplicity of dedicated hardware. Rather than making a phone app, his credit card sized audio player has a run time 40 hrs with standby of months.
Word files are a ‘post paper digital artifact’
I really enjoyed the talk from Adam Hyde of Coko Foundation. He explained in a friendly rant how 90% of scholarly content is supplied as Word files and not truly digital. His phrase was Word files are a ‘post paper digital artifact.’ But not just there to complain, Adam had three solutions that all looked worth finding out more about:
- Getting content from word into HTML – XSweet.coko.foundation was released two weeks ago.
- How to edit content in HTML including citations, notes, tracked changes etc. (that is, the pro tools that are missing from Google Docs) — An open source HTML word processor.
- How to get digital content it out into legacy formats like PDF —Automation and using the browser as a typesetting engine: pagedmedia.org
Other highlights included @gleephapp a phone app that features a real-time barcode scanner of ISBNs and even book spines to make the link from physical to digital and then allows recommendations. This app has just launched in France with 33,500 users and 20,0000 titles.
Volker Oppmann of mojoreads (@onkelvolker) showed their neat book sharing platform which actually pays its users 10% commission for any sale that comes from their recommendation. #eprdctn
We also heard that Readium has further goals including an update to the Readium CloudReader with support for audiobooks.
I’m very glad I made the trip and I hope to attend again next year but I must conclude by saying this: it amazes me that Adobe is not attending, supporting, contributing development effort and funding to EDRLab. Privately they would have so much to gain themselves from this modern open source reading system And publicly, surely Adobe putting a couple of full time developers in EDRLab Paris for a year or two would both demonstrate and garner respect and support of their paying customers and the wider publishing community.
I’ll be talking more about Readium and demoing R2 during my PePcon session in a couple of weeks time if you’re attending CreativeProWeek and into EPUB and ebook development.
Also feel free to contact me directly if you’d like more info and I’ll help where I can.
Postscript. Typescript (@typescriptlang) seems to be a the current programming language of choice. Microsoft, EDRLab, and many of the smaller developers presenting at DPUB were all using it and speaking highly of it. http://www.typescriptlang.org


 The 2019 edition of the
The 2019 edition of the 

 I anticipate that in some not-too-distant future, there will be similar validation/checking tools to help with the production of audio books. In her presentation, Wendy Reid (Kobo) walked us through the W3C audio books standardization effort, which includes a strong recognition of the need for a structured table of contents (not just a playlist of MP3 files!), accessible descriptions, as well as the potential of more advanced features like escapability and skippability (which are well-known concepts in DAISY Digital Talking Books)
I anticipate that in some not-too-distant future, there will be similar validation/checking tools to help with the production of audio books. In her presentation, Wendy Reid (Kobo) walked us through the W3C audio books standardization effort, which includes a strong recognition of the need for a structured table of contents (not just a playlist of MP3 files!), accessible descriptions, as well as the potential of more advanced features like escapability and skippability (which are well-known concepts in DAISY Digital Talking Books)